

Building a Smarter Weekly Meal Planner with AI
28 Apr 2025The FOMO about AI caught me. While I use Chat GPT and Claude for some of my daily tasks (even searching for things), I missed a good opportunity by not boarding the AI Agent development wave. Intuitively, my first question was: What should I do with my AI Agent?
- A brief context
- Honey, what do you want to eat this week?
- Iteration #1: A simple approach
- Iteration #2: Repeated dishes
- Iteration #3: Seasonal dishes
- Iteration #4: Refining the embeddings (part 1)
- Iteration #5: Testing the embeddings (part 1)
- Iteration #6: Refining the embeddings (part 2)
- Iteration #7: Testing the embeddings (part 2)
- Iteration #8: Prompts are too large
- Iteration #9: Improving the penalty filter
- Iteration #10: Moving to OpenAI’s o4-mini
- Iteration #11: External embedding models (part 1)
- Iteration #12: Testing the embeddings (part 3)
- Iteration #13: Refining the embeddings (part 3)
- Iteration #14: External embedding models (part 2)
- Iteration #15: The dish replacement bug
- Iteration #16: Scored dishes
- Conclusion
A brief context
Almost two years ago, we hired a chef who is in charge of our weekly meals, including lunch, dinner, and some extras, such as grocery shopping (fruits, vegetables, etc.). The modus operandi is straightforward: We have a WhatsApp group where we share with the chef what we want to eat this week, and sometimes, the chef does that job for us, prepping a potential list of meals. Then, we make some adjustments to that list. Since then, I have stored the whole chat history with all the dishes we ordered and were offered. One of the things we struggle with sometimes is answering the following question.
Honey, what do you want to eat this week?
While it may seem a pretty straightforward question, it requires a lot of work and coordination, given that we usually go out for dinner or are travelling. I found a good use case for my soon-to-be-born AI agent: an agent to build the weekly meals list so we don’t need to think about that anymore, feeding it with our two-year WhatsApp chat contents.
Iteration #1: A simple approach
The first iteration used Deepseek’s AI engine through the OpenAI Python library. Deepseek is fully compatible with the OpenAI endpoints, so it was a good idea even if I wanted to move to another AI engine.
With this first iteration, I just tried to load all the exported WhatsApp chats into an SQLite3 database by reading the file line by line. What a bad idea. While the import worked, the resultant embedding model was disastrous at best. While the WhatsApp group remains very silent most of the time, there is a lot of noise hanging around, like questions about which brand of olive oil to buy or if we want Greek yogurt or a normal one. Since I had no idea what I was doing, I built a relevant context getter from those embeddings. Then, the create_new_menu method will use the embeddings to craft a new menu for the week.
async def create_new_menu(chat_id: int) -> str:
try:
historical_context = get_relevant_context("generar menú semanal")
system_prompt = f"""
Eres un asistente que genera menús semanales para nuestro cocinero.
Contexto importante:
- El menú es para preparación semanal, en lo posible no deben repetirse con semanas anteriores cercanas
- Evitar alto contenido de gluten y lácteos (intolerancias)
- Puede incluir algunos platos con gluten/lácteos, pero deben ser minoría
- Siempre incluir los items de 'Y te pedimos' exactamente como se especifica
- El mensaje DEBE comenzar con "Hola! Te pasamos el menú para esta semana:"
- El mensaje DEBE terminar con "Gracias!"
- No incluir ninguna otra explicación, comentario o texto adicional
- No incluir si el plato tiene o no tiene gluten, o si tiene o no tiene lacteos.
Preferencias históricas:
{historical_context}
Requisitos estrictos:
- Estructura clara con números y asteriscos para los platos
- 10 platos principales variados
- Cada plato debe ser completo (proteína + acompañamiento)
- Incluir sección 'Y te pedimos' con los items exactos requeridos
Formato obligatorio:
1. Plato 1
2. Plato 2
...
3. Plato 10
Y te pedimos
4. pan de masa madre
5. maple de huevos de granja
6. 3-4 paltas
7. bananas
8. yogur griego
9. 3 manzanas
10. 2 duraznos
...
11. [otros items de tu lista]
"""
user_prompt = """
Por favor genera un menú semanal completo con:
- 10 platos principales variados
- Que sean aptos para preparación semanal
- Máximo 2 platos con gluten/lácteos
- Incluye la sección 'Y te pedimos' exactamente como se especificó
"""
response = deepseek_client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=TEMPERATURE,
top_p=TOP_P,
max_tokens=MAX_TOKENS
)
menu_text = response.choices[0].message.content
The results were far from ideal, but I was amazed by the power of the AI. This was the first working result:
🍽️ Tu menú semanal 🍽️
Hola \! Te pasamos el menú para esta semana:
1\. Curry de garbanzos con espinacas y leche de coco \+ arroz basmati
2\. Salmón al horno con costra de almendras \+ puré de coliflor
3\. Wok de tofu y vegetales \(pimiento, zanahoria, brócoli\) \+ fideos de arroz
4\. Milanesas de berenjena \(sin gluten\) \+ ensalada de rúcula y cherry
5\. Guiso de lentejas con zapallo y chorizo colorado \+ quinoa
6\. Pollo al limón con romero \+ papas rústicas al horno
7\. Tartar de palta y mango \+ crackers de semillas \(1 plato con gluten\)
8\. Estofado de ternera con hongos \+ puré de boniato
9\. Ensalada de quinoa con tomate, pepino y aceitunas \+ huevo pochado
10\. Pizza de harina de garbanzos \(1 plato con lácteos\) \+ mix de verdes
Y te pedimos
* pan de masa madre
* maple de huevos de granja
* 3\-4 paltas
* bananas
* 1kg de tomates cherry
* 1 frasco de almendras
* 1 paquete de quinoa
* 1 leche de coco
Gracias\!
Iteration #2: Repeated dishes
After playing for a few minutes with the bot, I found that it was repeating most of the dishes all the time. Sometimes they were repeated literally, and sometimes in different forms, example:
First round:
2\. Salmón al horno con costra de almendras \+ puré de coliflor y espinacas
Second round:
2\. Salmón al horno con costra de almendras \+ puré de coliflor
Third round:
2\. Salmón al horno con costra de almendras \+ puré de coliflor
Fourth round:
2. Salmón al horno con puré de coliflor y espárragos
So I started to refine the prompt, asking the engine to generate completely new weekly meals for today and to avoid recently offered dishes (I was storing the generated dishes in the SQLite database).

That improved the generation significantly, at least the same-index dishes were not repeated.
first round:
2. Wok de ternera con brócoli, zanahoria y castañas de cajú + fideos de arroz
second round:
2. Tartar de atún con palta y crackers de arroz
third round:
2. Pollo al curry verde con leche de coco y arroz jazmín
fourth round:
2. Pechuga de pollo rellena de espinacas y almendras + puré de boniato
Iteration #3: Seasonal dishes
After researching the recommended dishes, I discovered some ingredients were unavailable this season. So I thought of adding more context to the prompt, by asking the agent to mind about the season we are in:
today = datetime.datetime.now()
current_month = today.month
if 3 <= current_month <= 5:
season = "otoño"
elif 6 <= current_month <= 8:
season = "invierno"
elif 9 <= current_month <= 11:
season = "primavera"
else:
season = "verano"
system_prompt = f"""
...
- Estamos en {season}, considera ingredientes de temporada.
- Vivimos en Argentina. Es importante que elijas alimentos que se consigan aquí.
That new input improved the ingredient selection significantly. Now, the agent recommends Mangoes and avoids Pears in the summer.
Iteration #4: Refining the embeddings (part 1)
At this point, I briefly paused to think more about the embeddings, and I had an A-ha moment when I discovered that the get_relevant_context() method was returning a lot of nonsensical data, as in, data that was utterly useless as input to generate a new menu. While sometimes the context contained a few dishes, most of the time, there were non-contextual messages about bills or discussions about other things from the WhatsApp group. The first refining loop was to improve the message match pattern when creating the embeddings in the database:

Now the menu was getting way more consistent.
Hola! Te pasamos el menú para esta semana:
1. Merluza al horno con romero y puré de zapallo anco
2. Pollo al horno con piel crocante y ensalada de radicheta, pera y nueces
3. Wok de ternera con brócoli, zanahoria y jengibre + arroz yamaní
4. Budín de calabaza con huevo y semillas de amapola + mix de hojas verdes
5. Suprema de pollo rellena de espinaca y pasas de uva + puré de manzana y zanahoria
6. Ensalada tibia de garbanzos, berenjena asada, tomates secos y rúcula
7. Corvina a la plancha con salsa de maracuyá + brócoli al vapor
8. Tortilla de acelga y cebolla caramelizada + ensalada de remolacha rallada
9. Medallones de cerdo con reducción de manzana + coles de bruselas salteadas
10. Risotto de hongos portobellos con azafrán (usar arroz carnaroli)
Y te pedimos:
* pan de masa madre
* maple de huevos de granja
* yogur griego sin lactosa (2 sachets)
* 1kg bananas, 3 manzanas, 4 paltas, 2 peras
* leche de avena
* 1kilo de limones
* avena instantánea 1kilo
* hierbas frescas (romero, tomillo)
* 1/2kg de tomates cherry
* 1 durazno
Gracias!
Iteration #5: Testing the embeddings (part 1)
I started testing the embeddings generation with unittest and mocked some API calls. There, I discovered that the embeddings were utterly useless at this point. Now I have a lot of work to do.
def test_get_relevant_context(self):
from embeddings import load_or_create_embeddings, get_relevant_context
load_or_create_embeddings()
context = get_relevant_context("menú semanal", top_k=1)
self.assertIn("pollo", context.lower())
self.assertIn("tofu", context.lower())
self.assertIn("paltas", context.lower())
Iteration #6: Refining the embeddings (part 2)
With those new test cases, I started to refine the embeddings generation, once again, building smarter regexes to filter out unwanted data from the messages.
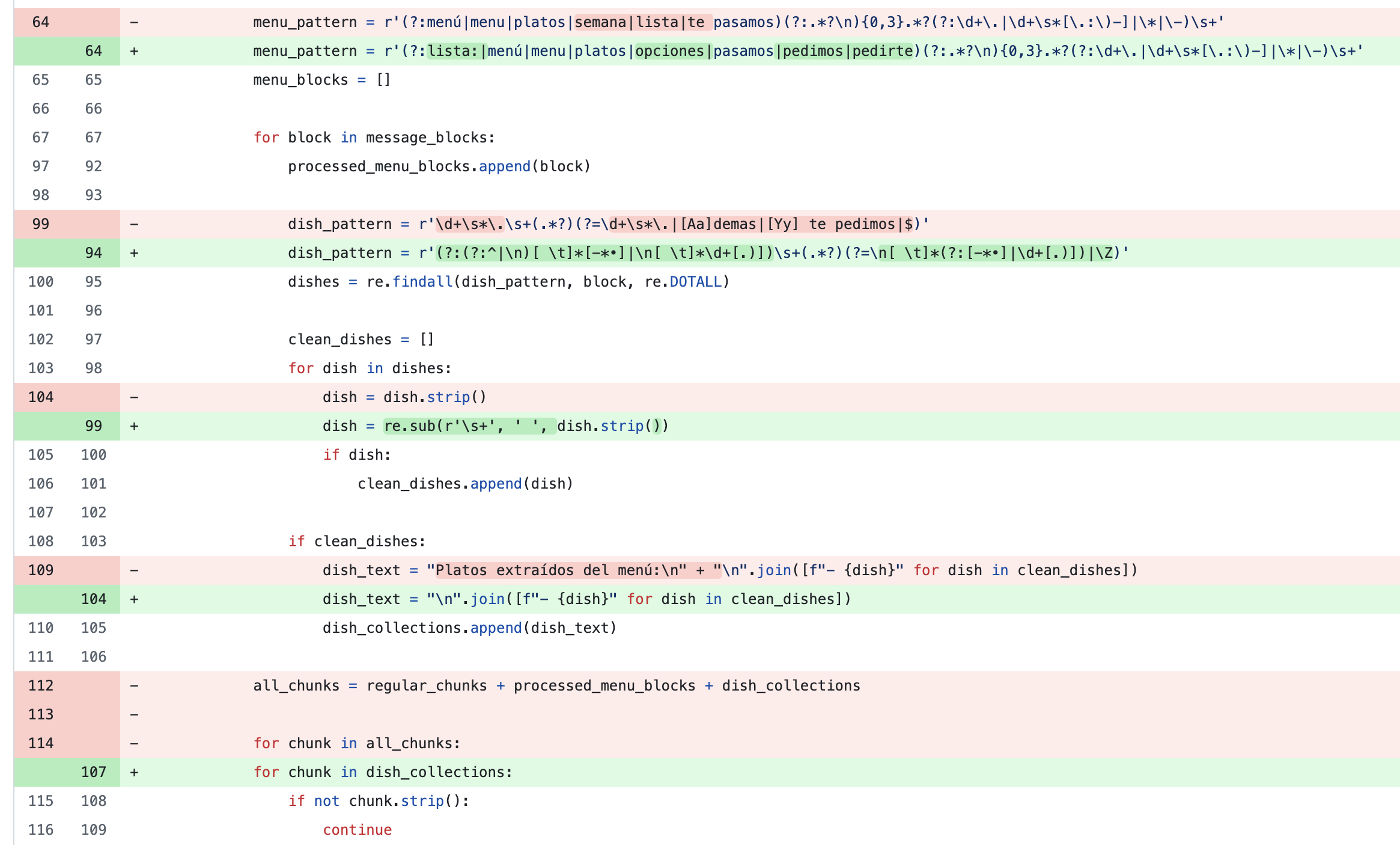
Iteration #7: Testing the embeddings (part 2)
After what happened before with the embeddings creation, I started to test the generated context:
def test_get_relevant_context_with_different_queries(self):
from embeddings import load_or_create_embeddings, get_relevant_context
load_or_create_embeddings()
# Test with menu-specific query
menu_context = get_relevant_context("platos para la semana", top_k=1)
self.assertIn("menú", menu_context.lower())
# Test with dish-specific query
dish_context = get_relevant_context("recetas con vegetales", top_k=1)
self.assertIn("wok de verduras", dish_context.lower())
# Test with ingredient-specific query
ingredient_context = get_relevant_context("platos con arroz", top_k=1)
self.assertIn("pollo al curry con arroz", ingredient_context.lower())
These three simple test cases gave me enough work to do to improve the embeddings generation.
Iteration #8: Prompts are too large
After many hours of coding and testing, I noticed system and user prompts were becoming huge, even contradictory in some cases, so I beat it with the simple stick. I leave just three things:
- The message format, how to start, end, what we cannot eat, and how many dishes to include.
- An array of query templates, with different starting messages to shuffle the generation.
- The context from the embeddings.
This started to generate less erratic menus, as before, many of the instructions conflicted.
Iteration #9: Improving the penalty filter
One task of the get_relevant_context() method is to penalize some dishes for repetition or for things we don’t eat. At this point, I made a few improvements to penalize already recommended dishes:
filtered_results = []
for sim, chunk in similarities[:top_k * 2]:
repetition_penalty = sum(
1 for dish in get_recent_dishes(14)
if dish.lower() in chunk.lower()
) * 0.2
final_score = sim - repetition_penalty
filtered_results.append((final_score, chunk))
filtered_results.sort(reverse=True, key=lambda x: x[0])
return "\n".join(chunk for score, chunk in filtered_results[:top_k])
Iteration #10: Moving to OpenAI’s o4-mini
The menu generation was alright at this point, but since I was using the OpenAI library, I was curious to test the OpenAI models. I was amazed at how fast o4-mini was compared to deepseek-chat. Also, the menu generation improved greatly, with more conciseness, alignment with our dietary requirements and limitations, and closeness to the instructions we gave to the API. I also played with different OpenAI models, gpt-4.1 was the best at this iteration.
Iteration #11: External embedding models (part 1)
For embeddings, I was using sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 through SentenceTransformer. While it was working alright, my Docker images weighed over 6 GB. So since I was already using the OpenAI API, I moved to text-embedding-3-large, as it is a good multilingual big model.
def get_openai_embedding(text: str) -> np.ndarray:
response = openai_client.embeddings.create(
input=[text],
model=EMBEDDING_MODEL
)
return np.array(response.data[0].embedding, dtype=np.float32)
I improved the embeddings testing with this new model, with new relevance and similarity cases.
Iteration #12: Testing the embeddings (part 3)
By using larger and remotely hosted models, I was able to do some better tests of relevance and similarity in the embeddings. However, I was disappointed at the results. “Chicken dish” and “Grilled chicken breast” are similar, at just a bit above 0.5.
def test_semantic_similarity(self):
"""Test semantic similarity between related culinary terms"""
pairs = [
("plato de pollo", "pechuga de pollo grillada", 0.5),
("ensalada de rúcula", "mix de verdes", 0.45),
("pure de papa", "pure de boniato", 0.7),
("risotto", "arroz cremoso", 0.5)
]
for term1, term2, min_similarity in pairs:
emb1 = get_openai_embedding(term1)
emb2 = get_openai_embedding(term2)
similarity = cosine_similarity([emb1], [emb2])[0][0]
self.assertGreaterEqual(similarity, min_similarity,
f"'{term1}' and '{term2}' should be similar")
def test_context_relevance(self):
"""Test that returned context is relevant to specific queries"""
test_cases = [
("lentejas", ["lenteja", "legumbre", "guiso"]),
("pescado", ["salmon", "trucha", "pesca", "mar"]),
("sin pepino", ["sin pepino"])
]
for query, expected_terms in test_cases:
context = get_relevant_context(query)
matches = sum(1 for term in expected_terms if term.lower() in context.lower())
self.assertGreaterEqual(matches, 1,
f"Query '{query}' should return context with relevant terms")
Anyway, this was a great starting point for benchmarking different embedding models in terms of similarity and relevance.
Iteration #13: Refining the embeddings (part 3)
While doing some self-code review on Saturday morning, I found a lot of nonsense about how I was generating the embeddings. The embeddings contained full WhatsApp messages, with all the dishes in one embedding and some embeddings with single dishes. Even so, embeddings with a chat message entirely unrelated to any dish or meal, so the simple stick strike again:

Iteration #14: External embedding models (part 2)
I was still sad about the latest testing rounds (See Iteration #12: Testing the embeddings (part 3)), where relevance and similarity values were very low, where I was expecting very high values. A bit more research led me to the following model: text-embedding-ada-002. Just by updating the embedding model, the similarity test results improved significantly:
test_semantic_similarity (test_embeddings_relevance.TestEmbeddings.test_semantic_similarity)
Test semantic similarity between related culinary terms ... 2025-04-27 20:47:20,979 - config - INFO - Setting up database: menu_bot.db
2025-04-27 20:47:20,980 - config - INFO - Using chat file: _chat.txt
2025-04-27 20:47:20,980 - config - INFO - Using database: menu_bot.db
2025-04-27 20:47:20,981 - config - INFO - Using existing 48 context embeddings
2025-04-27 20:47:21,992 - config - INFO - Semantic similarity, term1: plato de pollo, term2: pechuga de pollo grillada, similarity: 0.9127568602561951
2025-04-27 20:47:23,166 - config - INFO - Semantic similarity, term1: ensalada de rúcula, term2: mix de verdes, similarity: 0.8489089012145996
2025-04-27 20:47:23,991 - config - INFO - Semantic similarity, term1: pure de papa, term2: pure de boniato, similarity: 0.9051741361618042
2025-04-27 20:47:25,492 - config - INFO - Semantic similarity, term1: risotto, term2: arroz cremoso, similarity: 0.8769567608833313
2025-04-27 20:47:26,277 - config - INFO - Semantic similarity, term1: pesca, term2: pescado, similarity: 0.9344253540039062
2025-04-27 20:47:28,609 - config - INFO - Semantic similarity, term1: pesca blanca, term2: pescado, similarity: 0.8834995627403259
2025-04-27 20:47:29,319 - config - INFO - Semantic similarity, term1: trucha, term2: pescado, similarity: 0.8392864465713501
2025-04-27 20:47:30,703 - config - INFO - Semantic similarity, term1: salmon, term2: pesca, similarity: 0.8364511728286743
One thing that caught my attention was that newer models like text-embedding-3-small or text-embedding-3-large could not surpass the similarity levels achieved by text-embedding-ada-002.
Iteration #15: The dish replacement bug
One of the features of the AI agent is that you can ask it to replace a single meal from the list. Say you don’t like meal #3, you can ask for it to be replaced. What I was expecting was a different meal, but instead:
Original meal:
3. Medallones de cerdo laqueados con reducción de naranja y miel, acompañados de batatas asadas y ensalada tibia de repollitos de Bruselas.
Modifying meal #3...
3. Bondiola de cerdo desmenuzada con puré rústico de calabaza y ensalada fresca de rúcula, hinojo y naranjas.
Modifying meal #3...
3. Matambrito de cerdo al horno con batatas al romero y ensalada fresca de hojas verdes, hinojo y rodajas de naranja.
Modifying meal #3...
3. Bocaditos de cerdo al vapor con jengibre, cebollita de verdeo y salsa suave de soja, acompañados de ensalada de espinaca, hinojo y naranja.
Modifying meal #3...
3. Matambre de cerdo a la mostaza y miel con ensalada de rúcula, hinojo y gajos de naranja.
Amazing. This bad boy was mega consistent about the meal’s base ingredient: pork. That was an easy one:

Once I instructed the agent to offer a completely different meal, it started to behave better.
Iteration #16: Scored dishes
This iteration was added on May 28th, 2025.
Until now, the menus were generated based on strict and fixed prompts. We indeed used already-generated menus in the past to feed and improve the prompts, but they were not that good.
Having scored dishes would be better, so I added a one-to-five rating with stars for each menu. Now you can generate a menu, replace dishes, and then score it.
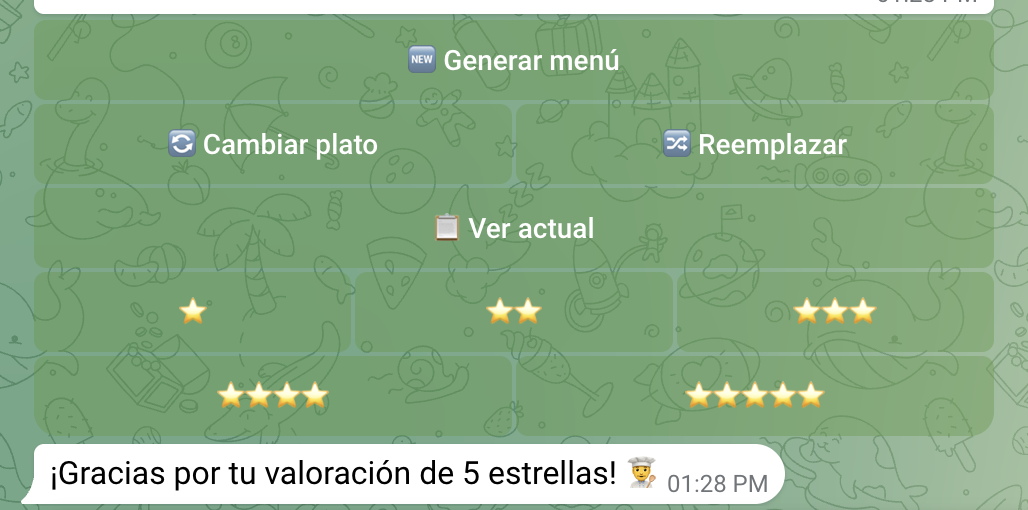
The rated dishes can be used later to feed the prompts for new menus:
def get_highly_rated_dishes(limit=5):
with sqlite3.connect(DB_NAME) as conn:
cursor = conn.cursor()
cursor.execute("""
SELECT m.menu_text
FROM menus m
JOIN menu_ratings r ON m.id = r.menu_id
WHERE r.rating >= 4
ORDER BY r.created_at DESC
LIMIT ?
""", (limit * 3,))
results = cursor.fetchall()
all_dishes = []
for row in results:
menu_text = row[0]
dishes = extract_dishes_from_menu(menu_text)
all_dishes.extend(dishes)
if all_dishes:
random.shuffle(all_dishes)
return all_dishes[:limit]
return []
Ratings are then converted to bonus points:
if chunk_hash in menu_ratings:
rating = menu_ratings[chunk_hash]
# Convert scale from 1-5 to a bonus: -0.2 to +0.2
rating_bonus = (rating - 3) * 0.1
logger.info(f"Found exact rating {rating} for chunk, applying bonus {rating_bonus}")
Now, highly rated dishes are used as dish suggestions in the menu generator method
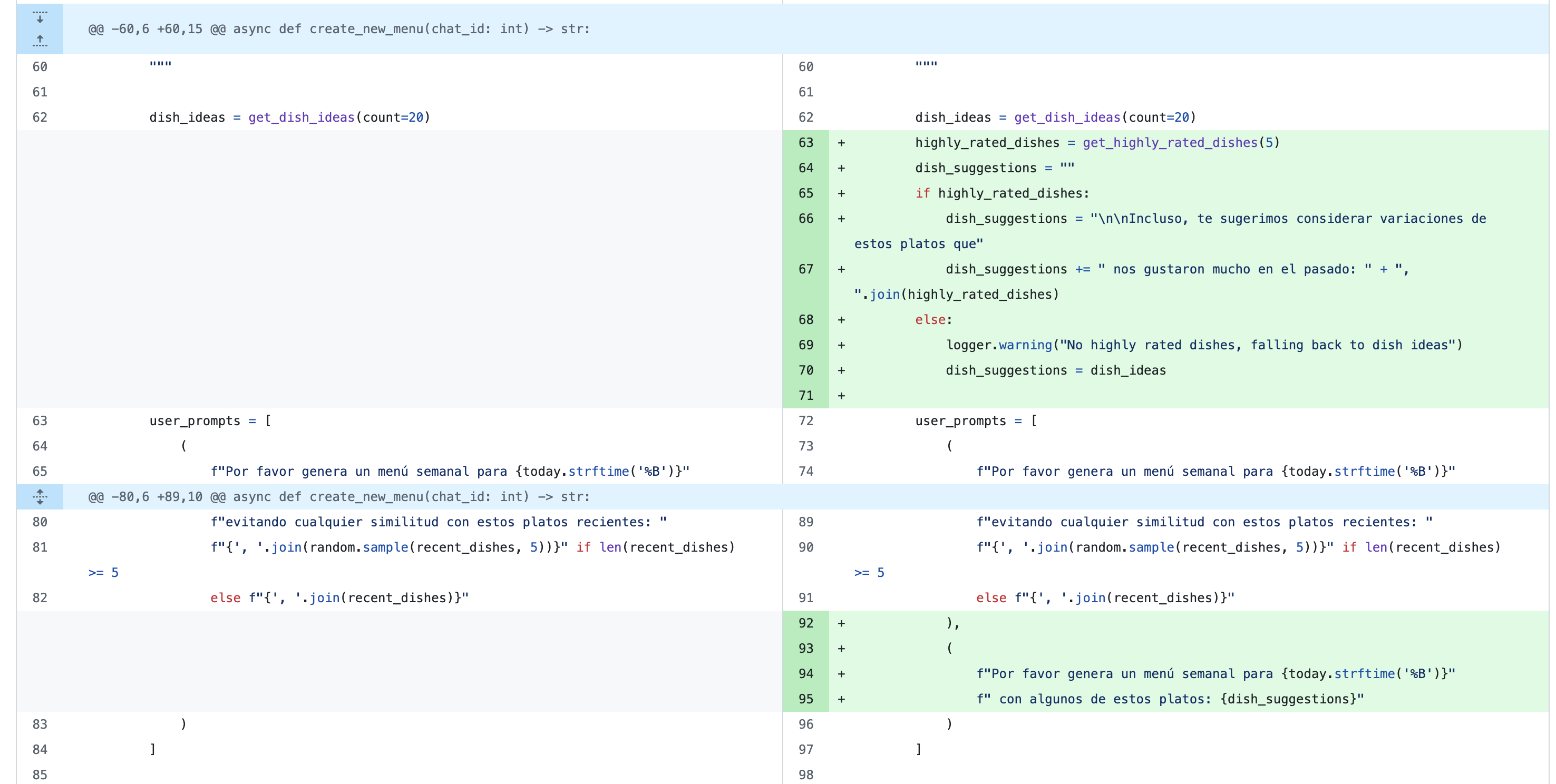
I am really happy with this inclusion, not only because the menus are way better than before, but also because I now have a more enriched database to play with.
Conclusion
Building this AI agent became a much bigger (and more fun) project than I initially imagined. What started as a quick solution to avoid thinking every week about “what are we eating?” became a deep dive into prompt engineering, embedding optimization, testing strategies, and AI model benchmarking.
Throughout this process, I realized two important things:
- First, even simple-sounding problems hide an incredible amount of nuance and complexity when you try to automate them properly.
- Second, AI agents are not just about throwing a model at a problem — they require iteration, testing, and a lot of attention to context, data quality, and user experience.
This project gave me real, hands-on experience with the practical side of AI development: dealing with messy data, imperfect models, and the never-ending cycle of build, test, refine. I hope to keep updating this post with my new findings.